MySQL 복제
1. 개요
MySQL Replication 은 하나의 서버(Source, 과거 Master)의 데이터를
하나 이상의 서버(Replica, 과거 Slave)와 동기화하는 기능
이는 단순한 성능 확장뿐만 아니라 다음과 같은 이점들을 가짐
High Availability (고가용성)
→ Primary(Source) 장애 발생 시 Replica를 승격(promote)하여 서비스 중단 시간을 최소화할 수 있음
Read Scalability (읽기 확장)
→ 읽기 트래픽을 다수 Replica로 분산함으로써 Primary의 부하를 줄이고 전체 처리량(throughput)을 확장할 수 있음
Disaster Recovery (재해 복구)
→ 다른 물리적 리전 또는 데이터센터에 Replica를 두어 지역 단위 장애 발생 시 데이터 손실을 최소화할 수 있음
백업 전략
→ 운영 중인 Primary 대신 Replica에서 백업을 수행하여 서비스 영향 없이 스냅샷 또는 덤프를 생성할 수 있음
분석 및 Reporting 분리
→ OLTP(트랜잭션 처리)와 OLAP(분석/리포팅) 워크로드를 분리하여 운영 트래픽과 분석 쿼리 간의 리소스 경쟁을 방지할 수 있음
복제의 핵심 목표는 한 서버의 데이터를 다른 서버와 지속적으로 동일하게 유지하는 것
2. 복제의 동작 방식
MySQL 복제는 크게 세 단계로 구성되며, 동작 방식은 다음과 같음
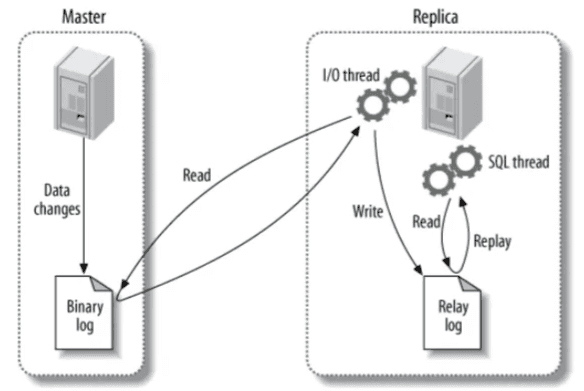
Source에서 Binary Log 기록
데이터 변경이 발생할 경우,
- 트랜잭션이 커밋되기 직전
- 변경 사항이 Binary Log에 기록됨
- Binary Log에 안전하게 기록된 후
- Storage Engine에 Commit 신호가 전달됨
Binary Log에는 트랜잭션 단위로 직렬화(serialized) 되어 기록됨
Replication은 실제 데이터 파일을 복사하는 것이 아니라,
변경 이벤트(Change Events) 를 기록하고 전파하는 방식으로 동작함
Replica의 I/O Thread가 복제 관련 이벤트를 수행
Replica와 관련된 주요 스레드 는 다음과 같음
- I/O Thread
- SQL Thread
I/O 스레드의 역할은 다음과 같음
- Source DB에 일반 클라이언트처럼 접속
- Binary Log 이벤트를 스트리밍 방식으로 읽음
- 읽은 내용을 Replica의 Relay Log에 기록
- Source와 동기화되면 Sleep 상태로 대기
- 새로운 이벤트가 발생하면 다시 수신
I/O 스레드는 Source → Replica로 복제와 관련된 이벤트를 전송하는 역할
Replica의 SQL Thread 동작
SQL 스레드의 역할은 다음과 같음
- Relay Log를 읽음
- 기록된 이벤트를 순차적으로 실행
- Source와 동일한 데이터 상태를 재현(복제 작업 수행)
SQL 스레드는 Relay Log를 통해 실제 데이터를 복제하는 역할 수행
복제(Replication) 전체 흐름 요약
- Source는 변경 내용을 Binary Log에 기록
- Replica의 I/O Thread가 이를 Relay Log로 복사
- Replica의 SQL Thread가 Relay Log를 실행
Source (Binary Log)
↓
Replica I/O Thread
↓
Replica Relay Log
↓
Replica SQL Thread
↓
Replica Data Files기본적으로 비동기(Asynchronous) 기반
물리 파일 복제가 아니라 논리적 변경 이벤트 복제
Replica는 독립적인 읽기 서버로 사용 가능
다수 Replica 확장 가능
MySQL Replication은 Source의 Binary Log 이벤트를 Replica가 Relay Log로 복사하고 재실행함으로써 데이터 동기화를 수행하는 구조